pyrand Documentation#

pyrand is a modular and high-performance C++/CUDA library distributed as a Python package that provides scalable randomized algorithms for the computationally expensive matrix functions in machine learning.
Note
pyrand is an experimental fork from imate python package. pyrand is under development and has not been released for production use.
Overview#
To learn more about pyrand functionality, see:
Supported Platforms#
Successful installation and tests performed on the following operating systems, architectures, and Python and PyPy versions:
Platform |
Arch |
Device |
Python Version |
PyPy Version |
Continuous Integration |
|||||
|---|---|---|---|---|---|---|---|---|---|---|
3.6 |
3.7 |
3.8 |
3.9 |
3.10 |
3.6 |
3.7 |
||||
Linux |
X86-64 |
CPU |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
|
GPU |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
|||
macOS |
X86-64 |
CPU |
✔ |
✔ |
✔ |
✔ |
✔ |
✖ |
✖ |
|
GPU |
✖ |
✖ |
✖ |
✖ |
✖ |
✖ |
✖ |
|||
Windows |
X86-64 |
CPU |
✔ |
✔ |
✔ |
✔ |
✔ |
✖ |
✖ |
|
GPU |
✔ |
✔ |
✔ |
✔ |
✔ |
✖ |
✖ |
|||



Python wheels for pyrand for all supported platforms and versions in the above are available through PyPI and Anaconda Cloud. If you need pyrand on other platforms, architectures, and Python or PyPy versions, raise an issue on GitHub and we build its Python Wheel for you.
Install#

Install with pip from PyPI:
pip install pyrand
Install with conda from Anaconda Cloud:
conda install -c s-ameli pyrand
For complete installation guide, see:
Docker#


The docker image comes with a pre-installed pyrand, an NVIDIA graphic driver, and a compatible version of CUDA Toolkit libraries.
Pull docker image from Docker Hub:
docker pull sameli/pyrand
For a complete guide, see:
GPU#
pyrand can run on CUDA-capable multi-GPU devices, which can be set up in several ways. Using the docker container is the easiest way to run pyrand on GPU devices. For a comprehensive guide, see:
The supported GPU micro-architectures and CUDA version are as follows:
Version \ Arch |
Fermi |
Kepler |
Maxwell |
Pascal |
Volta |
Turing |
Ampere |
Hopper |
|---|---|---|---|---|---|---|---|---|
CUDA 9 |
✖ |
✖ |
✖ |
✖ |
✖ |
✖ |
✖ |
✖ |
CUDA 10 |
✖ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
CUDA 11 |
✖ |
✖ |
✖ |
✔ |
✔ |
✔ |
✔ |
✔ |
Tutorials#
![]()
Launch online interactive notebook with Binder.
API Reference#
Check the list of functions, classes, and modules of pyrand with their usage, options, and examples.
Performance#
pyrand is scalable to very large matrices. Its core library for basic linear algebraic operations is faster than OpenBLAS, and its pseudo-random generator is a hundred-fold faster than the implementation in the standard C++ library.
Read about the performance of pyrand in practical applications:
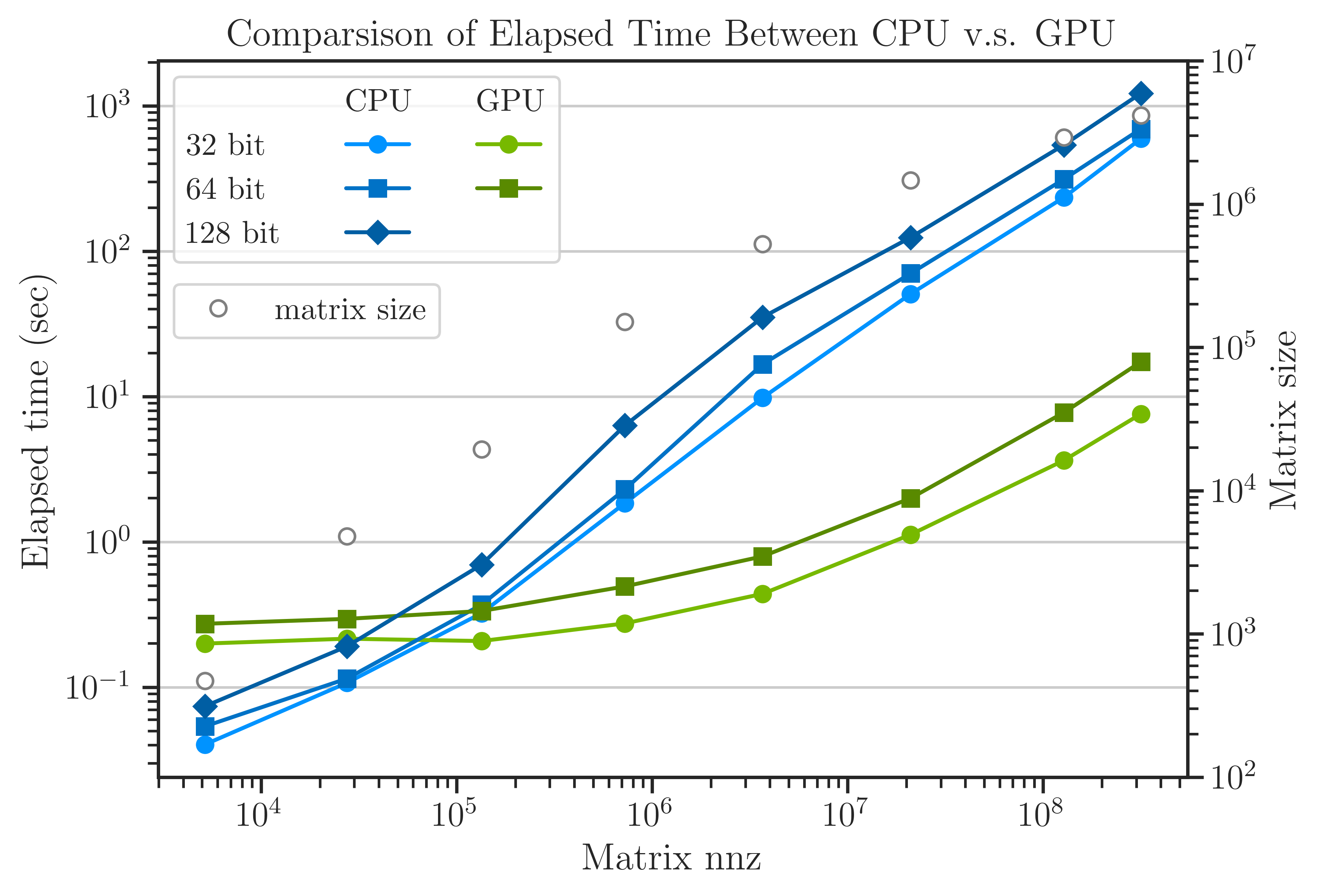
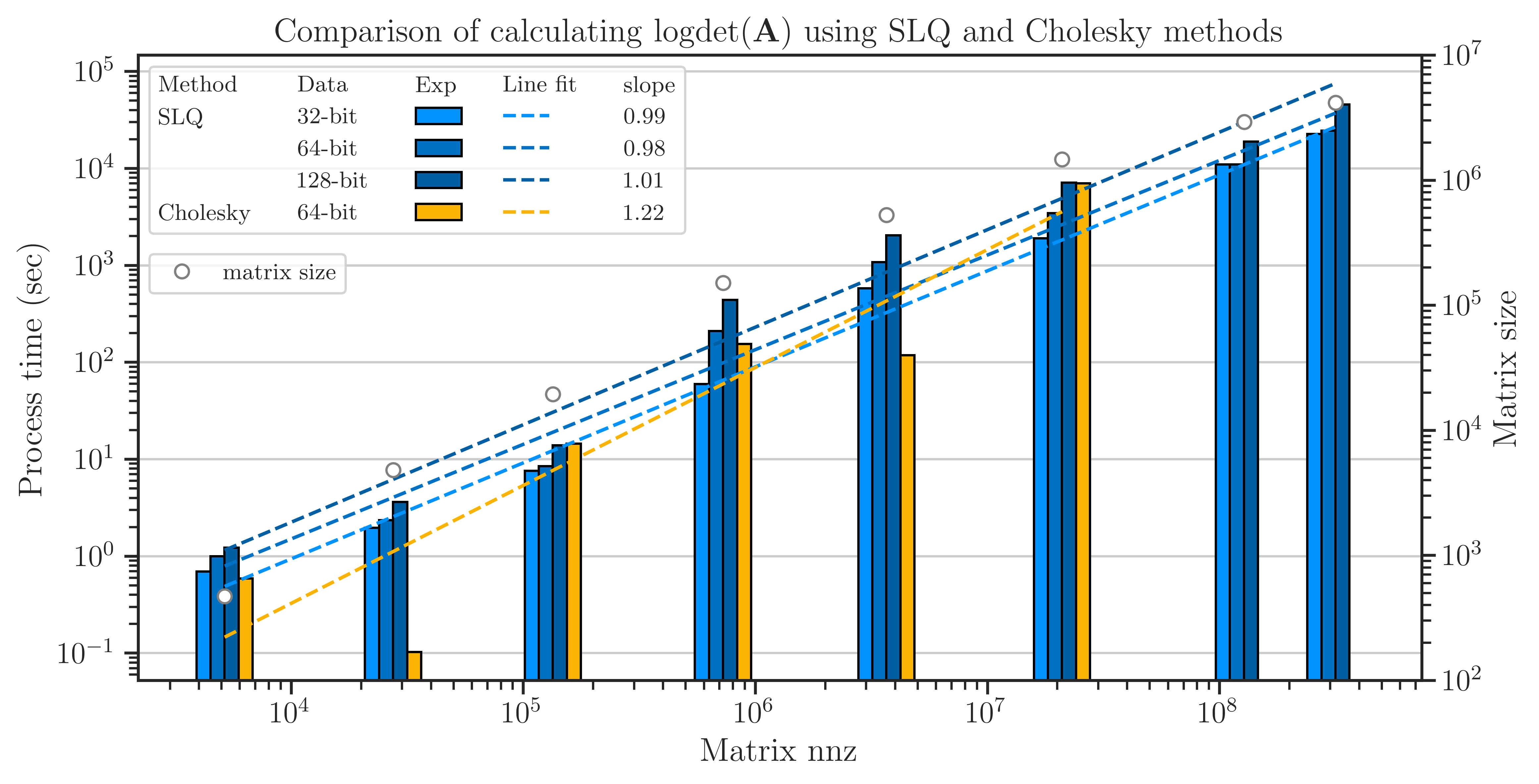
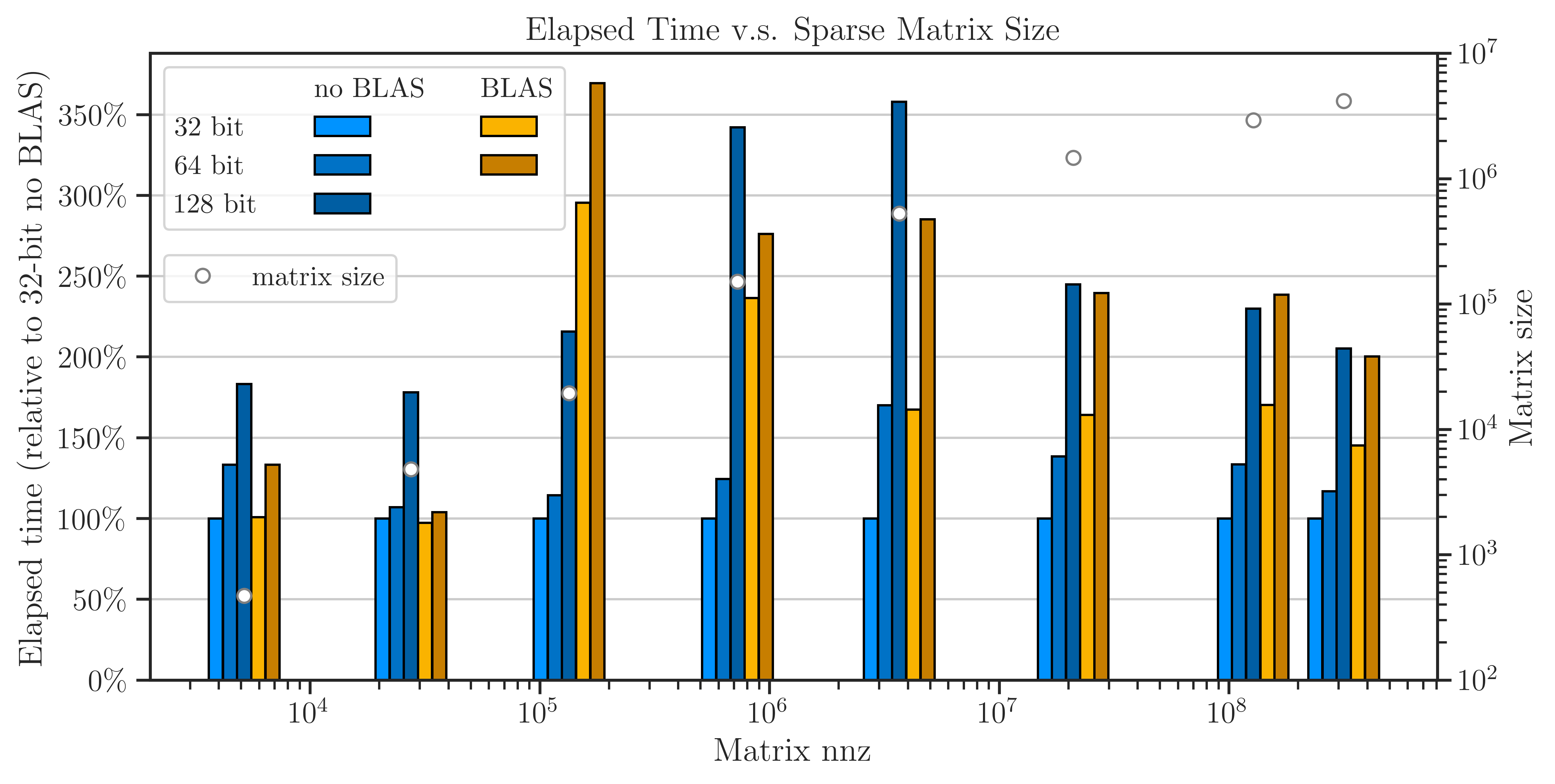
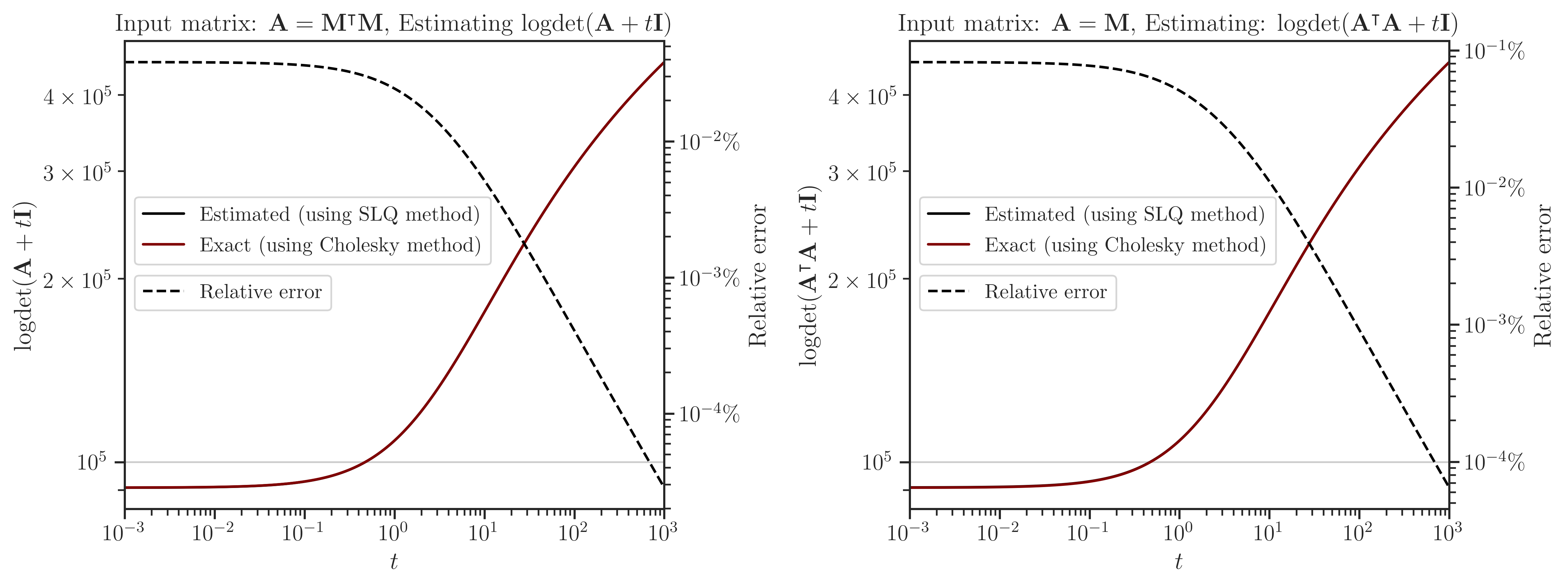
Features#
Matrices can be dense or sparse (CSR or CSC format), with 32-bit, 64-bit, or 128-bit data types, and stored either by row-ordering (C style) or column-ordering (Fortran style).
Matrices can be linear operators with parameters (see
pyrand.Matrixandpyrand.AffineMatrixFunctionclasses).Randomized algorithms using Hutchinson and stochastic Lanczos quadrature algorithms (see Overview)
Novel method to interpolate matrix functions. See Interpolation of Affine Matrix Functions.
Parallel processing both on shared memory and CUDA Capable multi-GPU devices.
Technical Notes#

The core of pyrand, which is implemented in C++ and NVIDIA CUDA framework, is a standalone modular library for high-performance low-level algebraic operations on linear operators (including matrices and affine matrix functions). This library provides a unified interface for computations on both CPU and GPU, a unified interface for dense and sparse matrices, a unified container for various data types, and fully automatic memory management and data transfer between CPU and GPU devices on demand. This library can be employed independently for projects other than pyrand. The Doxygen generated reference of C++/CUDA Classes and Namespaces of pyrand is available for developers.
The front-end interface of pyrand is implemented in Cython and Python (see Python API Reference for end-users).
Some notable implementation techniques used to develop pyrand are:
Polymorphic and curiously recurring template pattern programming (CRTP) technique.
OS-independent customized dynamic loading of CUDA libraries (as opposed to dynamic linking).
Static dispatching enables executing pyrand with and without CUDA on the user’s machine with the same pre-compiled pyrand installation.
Completely GIL-free Cython implementation.
Providing manylinux wheels build upon customized docker images with CUDA support (see manylinux CUDA 10 and manylinux CUDA 11 docker images on Docker Hub).
How to Contribute#
We welcome contributions via GitHub’s pull request. If you do not feel comfortable modifying the code, we also welcome feature requests and bug reports as GitHub issues.
Publications#
For information on how to cite pyrand, publications, and software packages that used pyrand, see:
License#

This project uses a BSD 3-clause license, in hopes that it will be accessible to most projects. If you require a different license, please raise an issue and we will consider a dual license.