|
imate
C++/CUDA Reference
|
|
imate
C++/CUDA Reference
|
A static class for vector operations, similar to level-1 operations of the BLAS library. This class acts as a templated namespace, where all member methods are public and static. More...
#include <c_vector_operations.h>
Static Public Member Functions | |
| static void | copy_vector (const DataType *RESTRICT input_vector, const LongIndexType vector_size, DataType *RESTRICT output_vector) |
| Copies a vector to a new vector. Result is written in-place. | |
| static void | copy_scaled_vector (const DataType *RESTRICT input_vector, const LongIndexType vector_size, const DataType scale, DataType *RESTRICT output_vector) |
| Scales a vector and stores to a new vector. | |
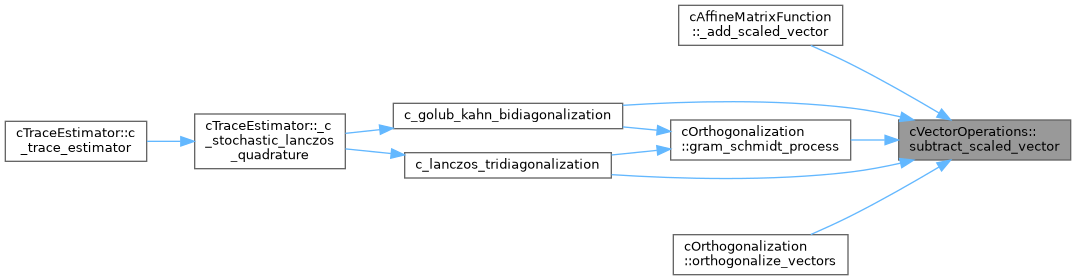
| static void | subtract_scaled_vector (const DataType *RESTRICT input_vector, const LongIndexType vector_size, const DataType scale, DataType *RESTRICT output_vector) |
| Subtracts the scaled input vector from the output vector. | |
| static DataType | inner_product (const DataType *RESTRICT vector1, const DataType *RESTRICT vector2, const LongIndexType vector_size) |
| Computes Euclidean inner product of two vectors. | |
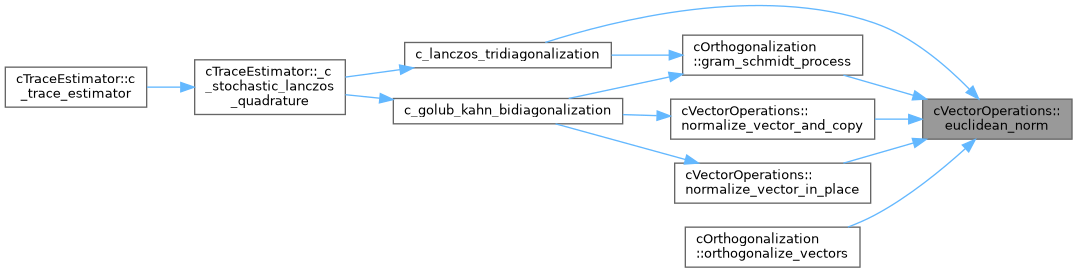
| static DataType | euclidean_norm (const DataType *RESTRICT vector, const LongIndexType vector_size) |
| Computes the Euclidean norm of a 1D array. | |
| static DataType | normalize_vector_in_place (DataType *RESTRICT vector, const LongIndexType vector_size) |
| Normalizes a vector based on Euclidean 2-norm. The result is written in-place. | |
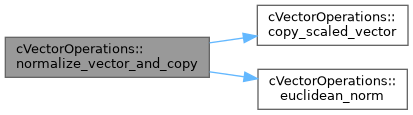
| static DataType | normalize_vector_and_copy (const DataType *RESTRICT vector, const LongIndexType vector_size, DataType *RESTRICT output_vector) |
| Normalizes a vector based on Euclidean 2-norm. The result is written into another vector. | |
A static class for vector operations, similar to level-1 operations of the BLAS library. This class acts as a templated namespace, where all member methods are public and static.
Definition at line 46 of file c_vector_operations.h.
|
static |
Scales a vector and stores to a new vector.
| [in] | input_vector | A 1D array |
| [in] | vector_size | Length of vector array |
| [in] | scale | Scale coefficient to the input vector. If this is equal to one, the function effectively becomes the same as copy_vector. |
| [out] | output_vector | Output vector (written in place). |
Definition at line 93 of file c_vector_operations.cpp.
Referenced by c_lanczos_tridiagonalization(), and cVectorOperations< DataType >::normalize_vector_and_copy().

|
static |
Copies a vector to a new vector. Result is written in-place.
| [in] | input_vector | A 1D array |
| [in] | vector_size | Length of vector array |
| [out] | output_vector | Output vector (written in place). |
Definition at line 45 of file c_vector_operations.cpp.
Referenced by c_lanczos_tridiagonalization().

|
static |
Computes the Euclidean norm of a 1D array.
The reduction variable (here, inner_prod ) is of the type long double. This is becase when DataType is float, the summation loses the precision, especially when the vector size is large. It seems that using long double is slightly faster than using double. The advantage of using a type with larger bits for the reduction variable is only sensible if the compiler is optimized with -O2 or -O3 flags.
Using a larger bit type for the reduction variable is very important for this function. If DataType is float, without such consideration, the result of estimation of trace can be completely wrong, just becase of the wrong norm results. For large array sizes, even libraries such as openblas does not compute the dot product accurately.
The chunk computation of the dot product (as seen in the code with chunk=5) improves the preformance with gaining twice speedup. This result is not much dependet on chunk. For example, chunk=10 also yields a similar result.
| [in] | vector | A pointer to 1D array |
| [in] | vector_size | Length of the array |
Definition at line 332 of file c_vector_operations.cpp.
References LARGE_ARRAY_SIZE, and USE_OPENMP.
Referenced by c_lanczos_tridiagonalization(), cOrthogonalization< DataType >::gram_schmidt_process(), cVectorOperations< DataType >::normalize_vector_and_copy(), cVectorOperations< DataType >::normalize_vector_in_place(), and cOrthogonalization< DataType >::orthogonalize_vectors().
|
static |
Computes Euclidean inner product of two vectors.
The reduction variable (here, inner_prod ) is of the type long double. This is becase when DataType is float, the summation loses the precision, especially when the vector size is large. It seems that using long double is slightly faster than using double. The advantage of using a type with larger bits for the reduction variable is only sensible if the compiler is optimized with -O2 or -O3 flags.
Using a larger bit type for the reduction variable is very important for this function. If DataType is float, without such consideration, the result of estimation of trace can be completely wrong, just becase of the wrong inner product results. For large array sizes, even libraries such as openblas does not compute the dot product accurately.
The chunk computation of the dot product (as seen in the code with chunk=5) improves the preformance with gaining twice speedup. This result is not much dependet on chunk. For example, chunk=10 also yields a similar result.
| [in] | vector1 | 1D array |
| [in] | vector2 | 1D array |
| [in] | vector_size | Length of array |
Definition at line 230 of file c_vector_operations.cpp.
References LARGE_ARRAY_SIZE, and USE_OPENMP.
Referenced by c_lanczos_tridiagonalization(), cOrthogonalization< DataType >::gram_schmidt_process(), and cOrthogonalization< DataType >::orthogonalize_vectors().

|
static |
Normalizes a vector based on Euclidean 2-norm. The result is written into another vector.
| [in] | vector | Input vector. |
| [in] | vector_size | Length of the input vector |
| [out] | output_vector | Output vector, which is the normalization of the input vector. |
Definition at line 472 of file c_vector_operations.cpp.
References cVectorOperations< DataType >::copy_scaled_vector(), and cVectorOperations< DataType >::euclidean_norm().
Referenced by c_golub_kahn_bidiagonalization().
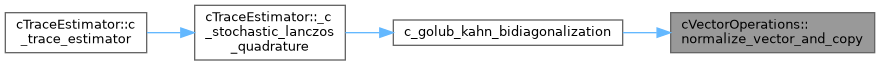
|
static |
Normalizes a vector based on Euclidean 2-norm. The result is written in-place.
| [in,out] | vector | Input vector to be normalized in-place. |
| [in] | vector_size | Length of the input vector |
Definition at line 414 of file c_vector_operations.cpp.
References cVectorOperations< DataType >::euclidean_norm().
Referenced by c_golub_kahn_bidiagonalization().


|
static |
Subtracts the scaled input vector from the output vector.
Performs the following operation:
\[ \boldsymbol{b} = \boldsymbol{b} - c \boldsymbol{a}, \]
where
| [in] | input_vector | A 1D array |
| [in] | vector_size | Length of vector array |
| [in] | scale | Scale coefficient to the input vector. |
| [in,out] | output_vector | Output vector (written in place). |
Definition at line 153 of file c_vector_operations.cpp.
References c_arithmetics::is_equal().
Referenced by cAffineMatrixFunction< DataType >::_add_scaled_vector(), c_golub_kahn_bidiagonalization(), c_lanczos_tridiagonalization(), cOrthogonalization< DataType >::gram_schmidt_process(), and cOrthogonalization< DataType >::orthogonalize_vectors().