|
imate
C++/CUDA Reference
|
|
imate
C++/CUDA Reference
|
Templated implenentations of several BLAS-type functions in CUDA. More...
Functions | |
| template<typename DataType , typename ComputeType > | |
| cudaError_t | cublasTgemv (cublasOperation_t trans, int m, int n, const DataType *RESTRICT alpha, const DataType *RESTRICT A, int lda, const DataType *RESTRICT x, int incx, const DataType *RESTRICT beta, DataType *RESTRICT y, int incy) |
| Performs \( \boldsymbol{y} = \alpha \text{op}(\mathbf{A})
\boldsymbol{x} + \beta \boldsymbol{y} \). | |
| template<typename DataType > | |
| cudaError_t | cublasTcopy (int n, const DataType *RESTRICT x, int incx, DataType *RESTRICT y, int incy) |
| Performs \( \boldsymbol{y} = \boldsymbol{x} \). | |
| template<typename DataType > | |
| cudaError_t | cublasTaxpy (int n, const DataType *RESTRICT alpha, const DataType *RESTRICT x, int incx, DataType *RESTRICT y, int incy) |
| Performs \( \boldsymbol{y} = \alpha \boldsymbol{x} +
\boldsymbol{y} \). | |
| template<typename DataType , typename ComputeType > | |
| cudaError_t | cublasTdot (int n, const DataType *RESTRICT x, int incx, const DataType *RESTRICT y, int incy, DataType *RESTRICT result) |
| Computes \( a = \boldsymbol{x} \cdot \boldsymbol{y} \). | |
| template<typename DataType , typename ComputeType > | |
| cudaError_t | cublasTnrm2 (int n, const DataType *RESTRICT x, int incx, DataType *RESTRICT result) |
| Computes \( a = \boldsymbol{x} \cdot \boldsymbol{x} \). | |
| template<typename DataType > | |
| cudaError_t | cublasTscal (int n, const DataType *RESTRICT alpha, DataType *RESTRICT x, int incx) |
| Performs \( \boldsymbol{x} = \alpha \boldsymbol{x}
\). | |
Templated implenentations of several BLAS-type functions in CUDA.
The motivation for re-implementing CuBLAS is that CUDA's CuBLAS library does not supports __half type and __nv_bfloat16 type for some of it functions. For instance, while there is support for level 3 functions, they do not provide level 2 and 1 functions with __half type.
The functions in this namespace provides some level 2 functions by implementing CUDA kernels from scratch. These implementations are templated with mixed precision computations where both the data types and inner computation types are templated. The data type is set by DatatType typename and the inner computation type is set by ComputeType typename.
Despite the generic templated functions, he main intent of these templates are to be used primarily for the missing types in CuBLAS, namely, the __half type (which is float16 type) and __nv_bfloat6 type (which is Google's bfloat16 type). But users may utilize these templates for any data and compute types.
The prefix convension for all functions in this namespace are cublasT (for instance cublasTgemv) where T here denotes template. In the CuBLAS API, this letter a placeholder for data type, such as S for single preicsion and D for double precision.
The functions in this namespace are the host codes. The kernel codes corresponding to each host code can be found in cublas_impl_kernels namespace.
| cudaError_t cublas_impl::cublasTaxpy | ( | int | n, |
| const DataType *RESTRICT | alpha, | ||
| const DataType *RESTRICT | x, | ||
| int | incx, | ||
| DataType *RESTRICT | y, | ||
| int | incy | ||
| ) |
Performs \( \boldsymbol{y} = \alpha \boldsymbol{x} + \boldsymbol{y} \).
This function is a custom implementation of cuBLAS's cublasSaxpy from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTaxpy_kernel .
| [in] | n | Size of array \( \boldsymbol{x} \). |
| [in] | alpha | The scalar parameter \( \alpha \). |
| [in] | x | Input vector \( \boldsymbol{x} \) stored on GPU device. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
| [out] | y | Output vector \( \boldsymbol{y} \) stored on GPU device. |
| [in] | incy | Stride between consecutive elements of \( \boldsymbol{y} \). |
Definition at line 223 of file cublas_impl.cu.
| cudaError_t cublas_impl::cublasTcopy | ( | int | n, |
| const DataType *RESTRICT | x, | ||
| int | incx, | ||
| DataType *RESTRICT | y, | ||
| int | incy | ||
| ) |
Performs \( \boldsymbol{y} = \boldsymbol{x} \).
This function is a custom implementation of cuBLAS's cublasScopy from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTcopy_kernel .
| [in] | n | Size of the array \( \boldsymbol{x} \). |
| [in] | x | Input vector \( \boldsymbol{x} \) stored on GPU device. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
| [out] | y | Output vector \( \boldsymbol{y} \) stored on GPU device. |
| [in] | incy | Stride between consecutive elements of \( \boldsymbol{y} \). |
Definition at line 169 of file cublas_impl.cu.
| cudaError_t cublas_impl::cublasTdot | ( | int | n, |
| const DataType *RESTRICT | x, | ||
| int | incx, | ||
| const DataType *RESTRICT | y, | ||
| int | incy, | ||
| DataType *RESTRICT | result | ||
| ) |
Computes \( a = \boldsymbol{x} \cdot \boldsymbol{y} \).
This function is a custom implementation of cuBLAS's cublasSdot from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTdot_kernel .
| [in] | n | Size of array \( \boldsymbol{x} \). |
| [in] | x | Input vector \( \boldsymbol{x} \) stored on GPU device. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
| [out] | y | Output vector \( \boldsymbol{y} \) stored on GPU device. |
| [in] | incy | Stride between consecutive elements of \( \boldsymbol{y} \). |
| [out] | result | The dot product of two vectors. |
Definition at line 277 of file cublas_impl.cu.
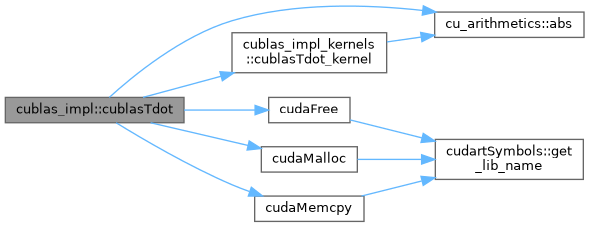
References cu_arithmetics::abs(), cublas_impl_kernels::cublasTdot_kernel(), cudaFree(), cudaMalloc(), and cudaMemcpy().
| cudaError_t cublas_impl::cublasTgemv | ( | cublasOperation_t | trans, |
| int | m, | ||
| int | n, | ||
| const DataType *RESTRICT | alpha, | ||
| const DataType *RESTRICT | A, | ||
| int | lda, | ||
| const DataType *RESTRICT | x, | ||
| int | incx, | ||
| const DataType *RESTRICT | beta, | ||
| DataType *RESTRICT | y, | ||
| int | incy | ||
| ) |
Performs \( \boldsymbol{y} = \alpha \text{op}(\mathbf{A}) \boldsymbol{x} + \beta \boldsymbol{y} \).
This function is a custom implementation of cuBLAS's cublasSgemv from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTgemv_kernel .
| [in] | trans | If set to CUBLAS_OP_N or CUBLAS_OP_T, the operator \( \mathbf{A} \) is not transposed or transposed, respectively. |
| [in] | m | Number of rows of matrix \( \mathbf{A} \). |
| [in] | n | Number of columns of matrix \( \mathbf{A} \). |
| [in] | alpha | The scalar parameter \( \alpha \). |
| [in] | A | Two-dimensional matrix \( \mathbf{A} \) stored on GPU device as one-dimensional array with column-major ordering. |
| [in] | lda | Leading dimension of two-dimensional matrix \( \mathbf{A} \). |
| [in] | x | Input vector \( \boldsymbol{x} \) stored on GPU device. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
| [in] | beta | The scalar parameter \( \beta \). |
| [out] | y | Output vector \( \boldsymbol{y} \) stored on GPU device. |
| [in] | incy | Stride between consecutive elements of \( \boldsymbol{y} \). |
Definition at line 77 of file cublas_impl.cu.
References cublas_impl_kernels::cublasTgemv_kernel().

| cudaError_t cublas_impl::cublasTnrm2 | ( | int | n, |
| const DataType *RESTRICT | x, | ||
| int | incx, | ||
| DataType *RESTRICT | result | ||
| ) |
Computes \( a = \boldsymbol{x} \cdot \boldsymbol{x} \).
This function is a custom implementation of cuBLAS's cublasSnrm2 from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTnrm2_kernel .
| [in] | n | Size of array \( \boldsymbol{x} \). |
| [in] | x | Input vector \( \boldsymbol{x} \) stored on GPU device. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
| [out] | result | The norm squared of a vector. |
Definition at line 344 of file cublas_impl.cu.
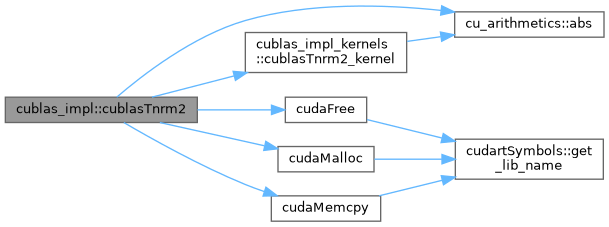
References cu_arithmetics::abs(), cublas_impl_kernels::cublasTnrm2_kernel(), cudaFree(), cudaMalloc(), and cudaMemcpy().
| cudaError_t cublas_impl::cublasTscal | ( | int | n, |
| const DataType *RESTRICT | alpha, | ||
| DataType *RESTRICT | x, | ||
| int | incx | ||
| ) |
Performs \( \boldsymbol{x} = \alpha \boldsymbol{x} \).
This function is a custom implementation of cuBLAS's cublasSscale from scratch. The corresponding kernel code can be found at cublas_impl_kernels::cublasTscal_kernel .
| [in] | n | Size of array \( \boldsymbol{x} \). |
| [in] | alpha | The scalar parameter \( \alpha \). |
| [in,out] | x | Input and output vector \( \boldsymbol{x} \) stored on GPU device. This vector is written in-place. |
| [in] | incx | Stride between consecutive elements of \( \boldsymbol{x} \). |
Definition at line 411 of file cublas_impl.cu.