|
imate
C++/CUDA Reference
|
|
imate
C++/CUDA Reference
|
Base class for linear operators. This class serves as interface for all derived classes. More...
#include <cu_linear_operator.h>

Public Member Functions | |
| cuLinearOperator () | |
| Default constructor. | |
| cuLinearOperator (const int num_gpu_devices_) | |
Constructor with setting num_rows and num_columns. | |
| virtual | ~cuLinearOperator () |
| Destructor. | |
| cublasHandle_t | get_cublas_handle () const |
This function returns a reference to the cublasHandle_t object. The object will be created, if it is not created already. | |
| void | set_parameters (DataType *parameters_) |
Sets the scalar parameter this->parameters. Parameter is initialized to NULL. However, before calling dot or transpose_dot functions, the parameters must be set. | |
| virtual DataType | get_eigenvalue (const DataType *known_parameters, const DataType known_eigenvalue, const DataType *inquiry_parameters) const =0 |
| virtual void | dot (const DataType *vector, DataType *product)=0 |
| virtual void | transpose_dot (const DataType *vector, DataType *product)=0 |
 Public Member Functions inherited from cLinearOperatorBase Public Member Functions inherited from cLinearOperatorBase | |
| cLinearOperatorBase () | |
| Default constructor. | |
| cLinearOperatorBase (const LongIndexType num_rows_, const LongIndexType num_columns_) | |
Constructor with setting num_rows and num_columns. | |
| virtual | ~cLinearOperatorBase () |
| Destructor. | |
| LongIndexType | get_num_rows () const |
| Returns the number of rows of the matrix. | |
| LongIndexType | get_num_columns () const |
| Returns the number of columns of the matrix. | |
| IndexType | get_num_parameters () const |
| Returns the number of parameters of the linear operator. | |
| FlagType | is_eigenvalue_relation_known () const |
| Returns a flag that determines whether a relation between the parameters of the operator and its eigenvalue(s) is known. | |
| virtual void | set_symmetry (FlagType symmetric)=0 |
Protected Member Functions | |
| int | query_gpu_devices () const |
| Before any numerical computation, this method chechs if any gpu device is available on the machine, or notifies the user if nothing was found. | |
| void | initialize_cublas_handle () |
Creates a cublasHandle_t object, if not created already. | |
| void | initialize_cusparse_handle () |
Creates a cusparseHandle_t object, if not created already. | |
Protected Attributes | |
| int | num_gpu_devices |
| bool | copied_host_to_device |
| cublasHandle_t * | cublas_handle |
| cusparseHandle_t * | cusparse_handle |
| DataType * | parameters |
| Protected Attributes inherited from cLinearOperatorBase | |
| const LongIndexType | num_rows |
| const LongIndexType | num_columns |
| FlagType | eigenvalue_relation_known |
| IndexType | num_parameters |
Base class for linear operators. This class serves as interface for all derived classes.
The prefix c in this class's name (and its derivatves), stands for the cpp code, intrast to the cu prefix, which stands for the cuda code. Most derived classes have a cuda counterpart.
Definition at line 63 of file cu_linear_operator.h.
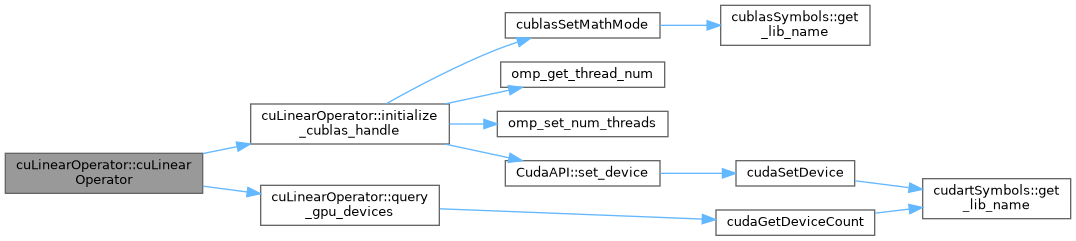
| cuLinearOperator< DataType >::cuLinearOperator | ( | ) |
Default constructor.
Definition at line 40 of file cu_linear_operator.cu.
References cuLinearOperator< DataType >::initialize_cublas_handle(), cuLinearOperator< DataType >::num_gpu_devices, and cuLinearOperator< DataType >::query_gpu_devices().

|
explicit |
Constructor with setting num_rows and num_columns.
| [in] | num_gpu_devices_ | Number of GPU devices to used for parallelization. |
Definition at line 73 of file cu_linear_operator.cu.
References cuLinearOperator< DataType >::initialize_cublas_handle(), cuLinearOperator< DataType >::num_gpu_devices, and cuLinearOperator< DataType >::query_gpu_devices().
|
virtual |
Destructor.
This function offloads data from GPUs.
Definition at line 120 of file cu_linear_operator.cu.
References cusparseDestroy(), omp_get_thread_num(), omp_set_num_threads(), and CudaAPI< ArrayType >::set_device().

|
pure virtual |
Implemented in cuCSCMatrix< DataType >, cuCSRMatrix< DataType >, cuDenseMatrix< DataType >, cuCSCAffineMatrixFunction< DataType >, cuCSRAffineMatrixFunction< DataType >, and cuDenseAffineMatrixFunction< DataType >.
Referenced by cu_golub_kahn_bidiagonalization(), and cu_lanczos_tridiagonalization().

| cublasHandle_t cuLinearOperator< DataType >::get_cublas_handle | ( | ) | const |
This function returns a reference to the cublasHandle_t object. The object will be created, if it is not created already.
The cublasHandle is needed for the client code (slq method) for vector operations on GPU. However, in this class, the cublasHandle_t might not be needed by it self if the derived class is a sparse matrix, becase the sparse matrix needs only cusparseHandle_t. In case if the cublasHandle_t is not created, it will be created for the purpose of the client codes.
Definition at line 205 of file cu_linear_operator.cu.
References CudaAPI< ArrayType >::get_device().
Referenced by cu_golub_kahn_bidiagonalization(), and cu_lanczos_tridiagonalization().


|
pure virtual |
Implemented in cuAffineMatrixFunction< DataType >, and cuMatrix< DataType >.
Referenced by cuTraceEstimator< DataType >::_cu_stochastic_lanczos_quadrature().

|
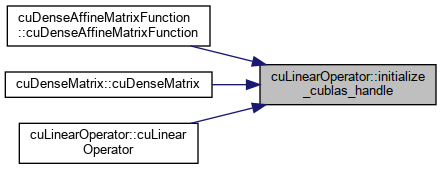
protected |
Creates a cublasHandle_t object, if not created already.
Definition at line 222 of file cu_linear_operator.cu.
References cublasSetMathMode(), omp_get_thread_num(), omp_set_num_threads(), and CudaAPI< ArrayType >::set_device().
Referenced by cuDenseAffineMatrixFunction< DataType >::cuDenseAffineMatrixFunction(), cuDenseAffineMatrixFunction< DataType >::cuDenseAffineMatrixFunction(), cuDenseMatrix< DataType >::cuDenseMatrix(), cuLinearOperator< DataType >::cuLinearOperator(), and cuLinearOperator< DataType >::cuLinearOperator().

|
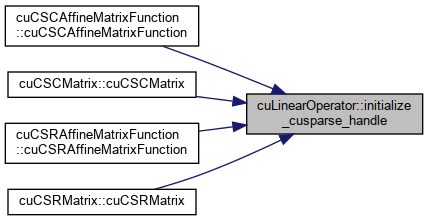
protected |
Creates a cusparseHandle_t object, if not created already.
Definition at line 269 of file cu_linear_operator.cu.
References cusparseCreate(), omp_get_thread_num(), omp_set_num_threads(), and CudaAPI< ArrayType >::set_device().
Referenced by cuCSCAffineMatrixFunction< DataType >::cuCSCAffineMatrixFunction(), cuCSCAffineMatrixFunction< DataType >::cuCSCAffineMatrixFunction(), cuCSCMatrix< DataType >::cuCSCMatrix(), cuCSRAffineMatrixFunction< DataType >::cuCSRAffineMatrixFunction(), cuCSRAffineMatrixFunction< DataType >::cuCSRAffineMatrixFunction(), and cuCSRMatrix< DataType >::cuCSRMatrix().

|
protected |
Before any numerical computation, this method chechs if any gpu device is available on the machine, or notifies the user if nothing was found.
Definition at line 314 of file cu_linear_operator.cu.
References cudaGetDeviceCount().
Referenced by cuLinearOperator< DataType >::cuLinearOperator(), and cuLinearOperator< DataType >::cuLinearOperator().

| void cuLinearOperator< DataType >::set_parameters | ( | DataType * | parameters_ | ) |
Sets the scalar parameter this->parameters. Parameter is initialized to NULL. However, before calling dot or transpose_dot functions, the parameters must be set.
| [in] | parameters_ | A pointer to the scalar or array of parameters. |
Definition at line 347 of file cu_linear_operator.cu.
Referenced by cuTraceEstimator< DataType >::_cu_stochastic_lanczos_quadrature().

|
pure virtual |
Implemented in cuCSCMatrix< DataType >, cuCSRMatrix< DataType >, cuDenseMatrix< DataType >, cuCSCAffineMatrixFunction< DataType >, cuCSRAffineMatrixFunction< DataType >, and cuDenseAffineMatrixFunction< DataType >.
Referenced by cu_golub_kahn_bidiagonalization().

|
protected |
Definition at line 100 of file cu_linear_operator.h.
|
protected |
Definition at line 101 of file cu_linear_operator.h.
|
protected |
Definition at line 102 of file cu_linear_operator.h.
|
protected |
Definition at line 99 of file cu_linear_operator.h.
Referenced by cuCSCMatrix< DataType >::cuCSCMatrix(), cuCSRMatrix< DataType >::cuCSRMatrix(), cuLinearOperator< DataType >::cuLinearOperator(), and cuLinearOperator< DataType >::cuLinearOperator().
|
protected |
Definition at line 103 of file cu_linear_operator.h.