|
imate
C++/CUDA Reference
|
|
imate
C++/CUDA Reference
|
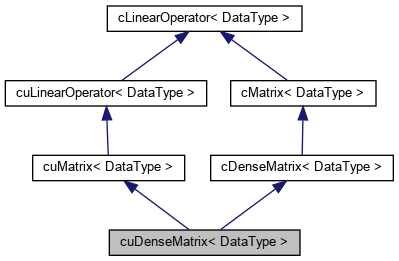
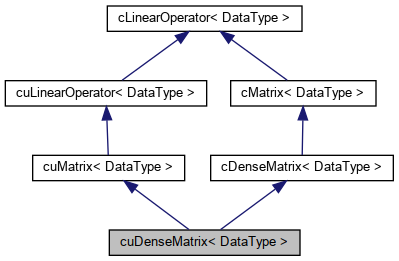
Container for dense matrices. More...
#include <cu_dense_matrix.h>
Public Member Functions | |
| cuDenseMatrix () | |
| Default constructor. | |
| cuDenseMatrix (const DataType *A_, const LongIndexType num_rows_, const LongIndexType num_columns_, const FlagType A_is_row_major_, const FlagType A_is_symmetric_, const int num_gpu_devices_) | |
| Constructor. | |
| virtual | ~cuDenseMatrix () |
| Destructor. This function removes data from GPU devices. | |
| virtual FlagType | is_identity_matrix () const |
| Checks whether the matrix is identity. | |
| virtual void | dot (const DataType *device_vector, DataType *device_product) |
| Matrix vector product. | |
| virtual void | dot_plus (const DataType *device_vector, const DataType alpha, DataType *device_product) |
| Matrix vector product written in place. | |
| virtual void | transpose_dot (const DataType *device_vector, DataType *device_product) |
| Transposed-matrix vector product. | |
| virtual void | transpose_dot_plus (const DataType *device_vector, const DataType alpha, DataType *device_product) |
| Transposed-matrix vector product written in place. | |
 Public Member Functions inherited from cuMatrix< DataType > Public Member Functions inherited from cuMatrix< DataType > | |
| cuMatrix () | |
| Default constructor. | |
| cuMatrix (const FlagType A_is_symmetric_) | |
| Constructor. | |
| virtual | ~cuMatrix () |
| Destructor. | |
| DataType | get_eigenvalue (const DataType *known_parameters, const DataType known_eigenvalue, const DataType *inquiry_parameters) const |
| This virtual function is implemented from its pure virtual function of the base class. In this class, this functio has no use and was only implemented so that this class be able to be instantiated (due to the pure virtual function). | |
| virtual void | set_symmetry (const FlagType symmetric) |
| Specify whether the matrix is symmetic or non-symmetric. | |
| Public Member Functions inherited from cuLinearOperator< DataType > | |
| cuLinearOperator () | |
| Default constructor. | |
| cuLinearOperator (const int num_gpu_devices_) | |
Constructor with setting num_rows and num_columns. | |
| virtual | ~cuLinearOperator () |
| Destructor. | |
| cublasHandle_t | get_cublas_handle () const |
This function returns a reference to the cublasHandle_t object. The object will be created, if it is not created already. | |
| void | set_parameters (DataType *parameters_) |
Sets the scalar parameter this->parameters. Parameter is initialized to NULL. However, before calling dot or transpose_dot functions, the parameters must be set. | |
| Public Member Functions inherited from cLinearOperatorBase | |
| cLinearOperatorBase () | |
| Default constructor. | |
| cLinearOperatorBase (const LongIndexType num_rows_, const LongIndexType num_columns_) | |
Constructor with setting num_rows and num_columns. | |
| virtual | ~cLinearOperatorBase () |
| Destructor. | |
| LongIndexType | get_num_rows () const |
| Returns the number of rows of the matrix. | |
| LongIndexType | get_num_columns () const |
| Returns the number of columns of the matrix. | |
| IndexType | get_num_parameters () const |
| Returns the number of parameters of the linear operator. | |
| FlagType | is_eigenvalue_relation_known () const |
| Returns a flag that determines whether a relation between the parameters of the operator and its eigenvalue(s) is known. | |
Protected Member Functions | |
| virtual void | copy_host_to_device () |
| Copies the member data from the host memory to the device memory. | |
| Protected Member Functions inherited from cuLinearOperator< DataType > | |
| int | query_gpu_devices () const |
| Before any numerical computation, this method chechs if any gpu device is available on the machine, or notifies the user if nothing was found. | |
| void | initialize_cublas_handle () |
Creates a cublasHandle_t object, if not created already. | |
| void | initialize_cusparse_handle () |
Creates a cusparseHandle_t object, if not created already. | |
Protected Attributes | |
| DataType ** | device_A |
| const DataType * | A |
| const FlagType | A_is_row_major |
| Protected Attributes inherited from cuMatrix< DataType > | |
| FlagType | A_is_symmetric |
| Protected Attributes inherited from cuLinearOperator< DataType > | |
| int | num_gpu_devices |
| bool | copied_host_to_device |
| cublasHandle_t * | cublas_handle |
| cusparseHandle_t * | cusparse_handle |
| DataType * | parameters |
| Protected Attributes inherited from cLinearOperatorBase | |
| const LongIndexType | num_rows |
| const LongIndexType | num_columns |
| FlagType | eigenvalue_relation_known |
| IndexType | num_parameters |
Container for dense matrices.
The cuDenseMatrix holds a two-dimensional dense matrix, and can perofrom matrix-vector product and transposed matrix-vector product.
Definition at line 43 of file cu_dense_matrix.h.
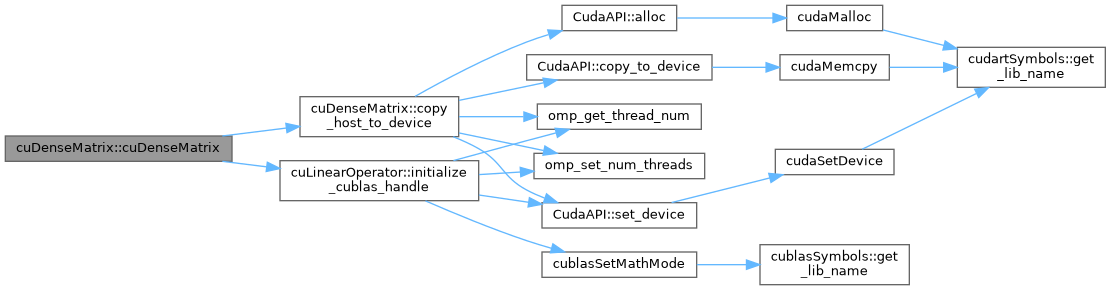
| cuDenseMatrix< DataType >::cuDenseMatrix | ( | ) |
Default constructor.
Definition at line 40 of file cu_dense_matrix.cu.
| cuDenseMatrix< DataType >::cuDenseMatrix | ( | const DataType * | A_, |
| const LongIndexType | num_rows_, | ||
| const LongIndexType | num_columns_, | ||
| const FlagType | A_is_row_major_, | ||
| const FlagType | A_is_symmetric_, | ||
| const int | num_gpu_devices_ | ||
| ) |
Constructor.
| [in] | A_ | 1D array that represents a 2D dense array with either C (row) major ordering or Fortran (column) major ordering. The major ordering should de defined by A_is_row_major flag. |
| [in] | num_rows_ | Number of rows of A |
| [in] | num_columns_ | Number of columns of A |
| [in] | A_is_row_major_ | Boolean, can be 0 or 1 as follows:
|
| [in] | A_is_symmetric_ | Boolean. If A is symmetric, set this value to 1, otherwise 0. |
| [in] | num_gpu_devices_ | Number of GPU devices to be utilized for parallelization. |
Definition at line 77 of file cu_dense_matrix.cu.
References cuDenseMatrix< DataType >::copy_host_to_device(), and cuLinearOperator< DataType >::initialize_cublas_handle().
|
virtual |
Destructor. This function removes data from GPU devices.
Definition at line 108 of file cu_dense_matrix.cu.
References CudaAPI< ArrayType >::del(), and CudaAPI< ArrayType >::set_device().

|
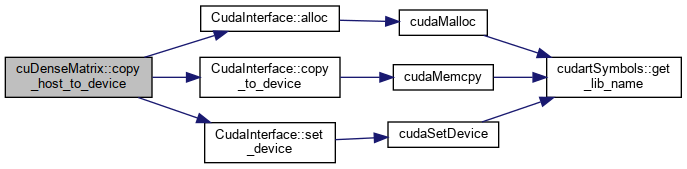
protectedvirtual |
Copies the member data from the host memory to the device memory.
Implements cuMatrix< DataType >.
Definition at line 137 of file cu_dense_matrix.cu.
References CudaAPI< ArrayType >::alloc(), CudaAPI< ArrayType >::copy_to_device(), omp_get_thread_num(), omp_set_num_threads(), and CudaAPI< ArrayType >::set_device().
Referenced by cuDenseMatrix< DataType >::cuDenseMatrix().

|
virtual |
Matrix vector product.
Performs the matrix vector product \( \boldsymbol{y} = \mathbf{A} \boldsymbol{x} \).
| [in] | device_vector | A one-dimensional input vector \( \boldsymbol{x} \) with size the of the number of columns of the matrix \( \mathbf{A} \). This array should be on the GPU device. |
| [out] | device_product | A one-dimensional output vector \( \boldsymbol{y} \) with the size of the number of rows of \( \mathbf{A} \). This vector will be overwritten. This array should be on the GPU device. |
Implements cuLinearOperator< DataType >.
Definition at line 333 of file cu_dense_matrix.cu.
References cuMatrixOperations< DataType >::dense_matvec(), and CudaAPI< ArrayType >::get_device().

|
virtual |
Matrix vector product written in place.
Performs the matrix vector product \( \boldsymbol{y} = \boldsymbol{y} + \alpha \mathbf{A} \boldsymbol{x} \).
| [in] | device_vector | A one-dimensional input vector \( \boldsymbol{x} \) with size the of the number of columns of the matrix \( \mathbf{A} \). This array should be on GPU device. |
| [in] | alpha | A scalar. |
| [out] | device_product | A one-dimensional output vector \( \boldsymbol{y} \) with the size of the number of rows of \( \mathbf{A} \). This array should be on GPU device. |
Implements cuMatrix< DataType >.
Definition at line 378 of file cu_dense_matrix.cu.
References cuMatrixOperations< DataType >::dense_matvec_plus(), and CudaAPI< ArrayType >::get_device().

|
virtual |
Checks whether the matrix is identity.
The identity check is primarily performed in the cAffineMatrixFunction class.
1 if the input matrix is identity, and 0 otherwise.Implements cuMatrix< DataType >.
Definition at line 193 of file cu_dense_matrix.cu.
References cu_arithmetics::is_equal().

|
virtual |
Transposed-matrix vector product.
Performs the matrix vector product \( \boldsymbol{y} = \mathbf{A}^{\intercal} \boldsymbol{x} \).
| [in] | device_vector | A one-dimensional input vector \( \boldsymbol{x} \) with size the of the number of columns of the matrix \( \mathbf{A} \). This array should be in GPU device. |
| [out] | device_product | A one-dimensional output vector \( \boldsymbol{y} \) with the size of the number of rows of \( \mathbf{A} \). This vector will be overwritten. This array should be on GPU device. |
Implements cuLinearOperator< DataType >.
Definition at line 423 of file cu_dense_matrix.cu.
References cuMatrixOperations< DataType >::dense_transposed_matvec(), and CudaAPI< ArrayType >::get_device().

|
virtual |
Transposed-matrix vector product written in place.
Performs the matrix vector product \( \boldsymbol{y} = \boldsymbol{y} + \alpha \mathbf{A}^{\intercal} \boldsymbol{x} \).
| [in] | device_vector | A one-dimensional input vector \( \boldsymbol{x} \) with size the of the number of columns of the matrix \( \mathbf{A} \). This array should be on GPU device. |
| [in] | alpha | A scalar. |
| [out] | device_product | A one-dimensional output vector \( \boldsymbol{y} \) with the size of the number of rows of \( \mathbf{A} \). This array should be on GPU device. |
Implements cuMatrix< DataType >.
Definition at line 469 of file cu_dense_matrix.cu.
References cuMatrixOperations< DataType >::dense_transposed_matvec_plus(), and CudaAPI< ArrayType >::get_device().

|
protected |
Definition at line 87 of file cu_dense_matrix.h.
|
protected |
Definition at line 88 of file cu_dense_matrix.h.
|
protected |
Definition at line 86 of file cu_dense_matrix.h.