|
imate
C++/CUDA Reference
|
|
imate
C++/CUDA Reference
|
A static class to compute the trace of implicit matrix functions using stochastic Lanczos quadrature method. This class acts as a templated namespace, where the member methods is public and static. The internal private member functions are also static. More...
#include <cu_trace_estimator.h>
Static Public Member Functions | |
| static FlagType | cu_trace_estimator (cuLinearOperator< DataType > *A, DataType *parameters, const IndexType num_inquiries, const Function *matrix_function, const FlagType gram, const DataType exponent, const FlagType orthogonalize, const int64_t seed, const IndexType lanczos_degree, const DataType lanczos_tol, const IndexType min_num_samples, const IndexType max_num_samples, const DataType error_atol, const DataType error_rtol, const DataType confidence_level, const DataType outlier_significance_level, const IndexType num_threads, const IndexType num_gpu_devices, DataType *trace, DataType *error, DataType **samples, IndexType *processed_samples_indices, IndexType *num_samples_used, IndexType *num_outliers, FlagType *converged, double &alg_wall_time) |
| Stochastic Lanczos quadrature method to estimate trace of a function of a linear operator. Both function and the linear operator can be defined with parameters. | |
Static Private Member Functions | |
| static void | _cu_stochastic_lanczos_quadrature (cuLinearOperator< DataType > *A, DataType *parameters, const IndexType num_inquiries, const Function *matrix_function, const FlagType gram, const DataType exponent, const FlagType orthogonalize, const IndexType lanczos_degree, const DataType lanczos_tol, RandomNumberGenerator &random_number_generator, DataType *random_vector, FlagType *converged, DataType *trace_estimate) |
| For a given random input vector, computes one Monte-Carlo sample to estimate trace using Lanczos quadrature method. | |
A static class to compute the trace of implicit matrix functions using stochastic Lanczos quadrature method. This class acts as a templated namespace, where the member methods is public and static. The internal private member functions are also static.
Definition at line 39 of file cu_trace_estimator.h.
|
staticprivate |
For a given random input vector, computes one Monte-Carlo sample to estimate trace using Lanczos quadrature method.
| [in] | A | An instance of a class derived from LinearOperator class. This object will perform the matrix-vector operation and/or transposed matrix-vector operation for a linear operator. The linear operator can represent a fixed matrix, or a combination of matrices together with some given parameters. |
| [in] | parameters | The parameters of the linear operator A. The size of this array is num_parameters*num_inquiries where num_parameters is the number of parameters that define the linear operator A, and num_inquiries is the number of different set of parameters to compute trace on different parametrized operators. The j-th set of parameters are stored in parameters[j*num_parameters:(j+1)*num_parameters]. That is, this array is contiguous over each batch of parameters. |
| [in] | num_inquiries | The number of batches of parameters. This function computes num_inquiries values of trace corresponding to different batch of parameters of the linear operator A. Hence, the number of output trace is num_inquiries. Hence, it is the number of columns of the output array samples. |
| [in] | matrix_function | An instance of Function class which has the function function. This function defines the matrix function, and operates on scalar eigenvalues of the matrix. |
| [in] | gram | Flag indicating whether the linear operator A is Gramian. If the linear operator is:
|
| [in] | exponent | The exponent parameter p in the trace of the expression \( f((\mathbf{A} + t \mathbf{B})^p) \). The exponent is a real number and by default it is set to 1.0. |
| [in] | orthogonalize | Indicates whether to orthogonalize the orthogonal eigenvectors during Lanczos recursive iterations.
|
| [in] | lanczos_degree | The number of Lanczos recursive iterations. The operator A is reduced to a square tridiagonal (or bidiagonal) matrix of the size lanczos_degree. The eigenvalues (or singular values) of this reduced matrix is computed and used in the stochastic Lanczos quadrature method. The larger Lanczos degre leads to a better estimation. The computational cost is quadratically increases with the lanczos degree. |
| [in] | lanczos_tol | The tolerance to stop the Lanczos recursive iterations before the end of iterations reached. If the tolerance is not met, the iterations (total of lanczos_degree iterations) continue till end. |
| [in] | random_number_generator | Generates random numbers that fills random_vector. In each parallel thread, an independent sequence of random numbers are generated. This object should be initialized by num_threads. |
| [in] | random_vector | A 1D vector of the size of matrix A. The Lanczos iterations start off from this random vector. Each given random vector is used per a Monte-Carlo computation of the SLQ method. In the Lanczos iterations, other vectors are generated orthogonal to this initial random vector. This array is filled inside this function. |
| [out] | converged | 1D array of the size of the number of columns of samples. Each element indicates which column of samples has converged to the tolerance criteria. Normally, if the num_samples used is less than max_num_samples, it indicates that the convergence has reached. |
| [out] | trace_estimate | 1D array of the size of the number of columns of samples array. This array constitures each row of samples array. Each element of trace_estimates is the estimated trace for each parameter inquiry. |
Definition at line 437 of file cu_trace_estimator.cu.
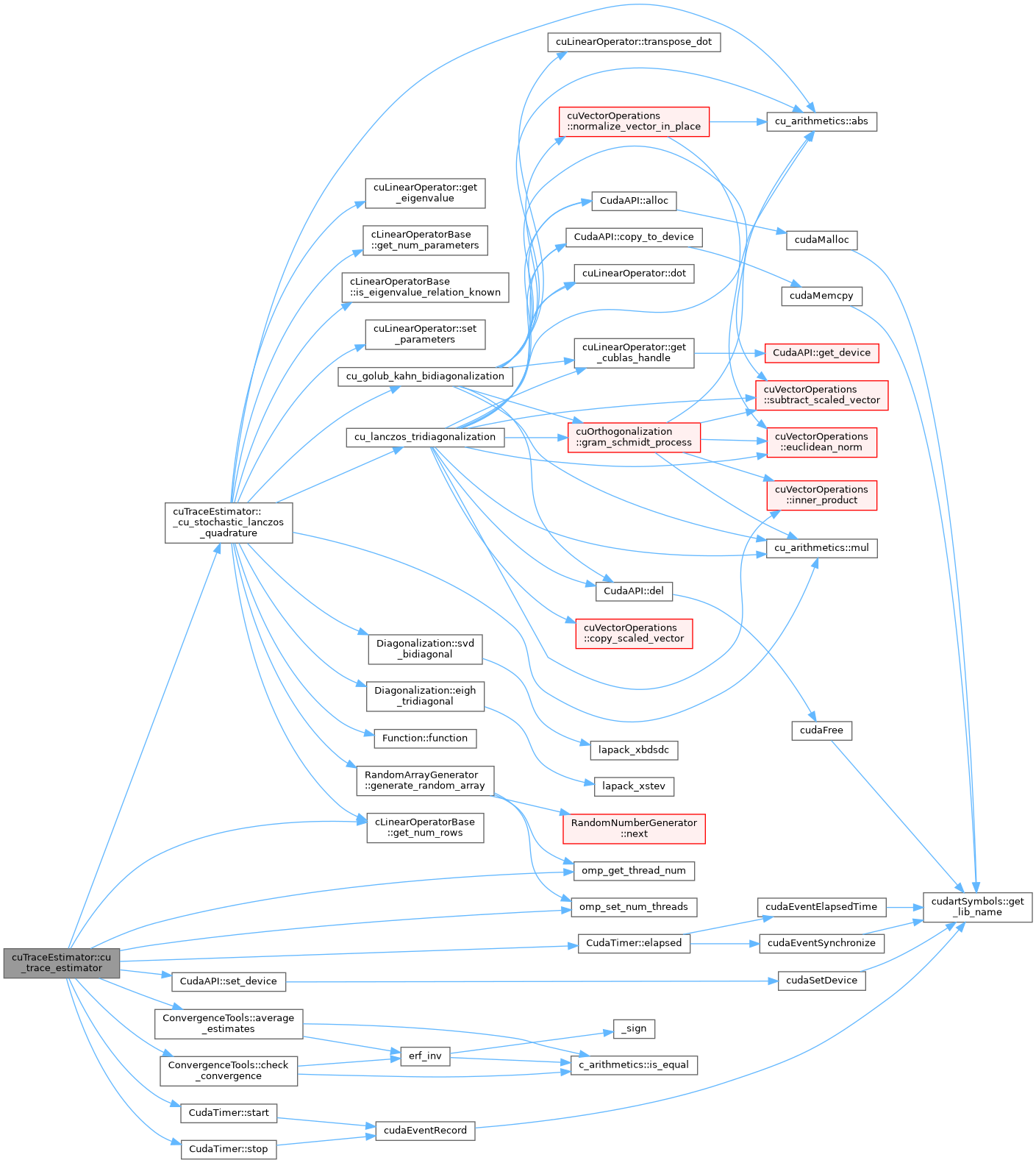
References cu_arithmetics::abs(), cu_golub_kahn_bidiagonalization(), cu_lanczos_tridiagonalization(), Diagonalization< DataType >::eigh_tridiagonal(), Function::function(), RandomArrayGenerator< DataType >::generate_random_array(), cuLinearOperator< DataType >::get_eigenvalue(), cLinearOperatorBase::get_num_parameters(), cLinearOperatorBase::get_num_rows(), cLinearOperatorBase::is_eigenvalue_relation_known(), cu_arithmetics::mul(), cuLinearOperator< DataType >::set_parameters(), and Diagonalization< DataType >::svd_bidiagonal().
Referenced by cuTraceEstimator< DataType >::cu_trace_estimator().

|
static |
Stochastic Lanczos quadrature method to estimate trace of a function of a linear operator. Both function and the linear operator can be defined with parameters.
Multiple batches of parameters of the linear operator can be passed to this function. In such a case, the output trace is an array of the of the number of the inquired parameters.
The stochastic estimator computes multiple samples of trace and the final result is the average of the samples. This function outputs both the samples of estimated trace values (in samples array) and their average (in trace array).
| [in] | A | An instance of a class derived from LinearOperator class. This object will perform the matrix-vector operation and/or transposed matrix-vector operation for a linear operator. The linear operator can represent a fixed matrix, or a combination of matrices together with some given parameters. |
| [in] | parameters | The parameters of the linear operator A. The size of this array is num_parameters*num_inquiries where num_parameters is the number of parameters that define the linear operator A, and num_inquiries is the number of different set of parameters to compute trace on different parametrized operators. The j-th set of parameters are stored in parameters[j*num_parameters:(j+1)*num_parameters]. That is, this array is contiguous over each batch of parameters. |
| [in] | num_inquiries | The number of batches of parameters. This function computes num_inquiries values of trace corresponding to different batch of parameters of the linear operator A. Hence, the number of output trace is num_inquiries. Hence, it is the number of columns of the output array samples. |
| [in] | matrix_function | An instance of Function class which has the function function. This function defines the matrix function, and operates on scalar eigenvalues of the matrix. |
| [in] | gram | Flag indicating whether the linear operator A is Gramian. If the linear operator is:
|
| [in] | exponent | The exponent parameter p in the trace of the expression \( f((\mathbf{A} + t \mathbf{B})^p) \). The exponent is a real number and by default it is set to 1.0. |
| [in] | orthogonalize | Indicates whether to orthogonalize the orthogonal eigenvectors during Lanczos recursive iterations.
|
| [in] | seed | A non-negative integer to be used as seed to initiate the generation of sequences of peudo-random numbers in the algorithm. This is useful to make the result of the randomized algorithm to be reproducible. If a negative integer is given, the given seed value is ignored and the current processor time is used as the seed to initiate he generation random number sequences. In this case, the result is not reproducible, rather, is pseudo-random. |
| [in] | lanczos_degree | The number of Lanczos recursive iterations. The operator A is reduced to a square tridiagonal (or bidiagonal) matrix of the size lanczos_degree. The eigenvalues (or singular values) of this reduced matrix is computed and used in the stochastic Lanczos quadrature method. The larger Lanczos degree leads to a better estimation. The computational cost is quadratically increases with the lanczos degree. |
| [in] | lanczos_tol | The tolerance to stop the Lanczos recursive iterations before the end of iterations reached. If the tolerance is not met, the iterations (total of lanczos_degree iterations) continue till end. |
| [in] | min_num_samples | Minimum number of times that the trace estimation is repeated. Within the min number of samples, the Monte-Carlo continues even if convergence is reached. |
| [in] | max_num_samples | The number of times that the trace estimation is repeated. The output trace value is the average of the samples. Hence, this is the number of rows of the output array samples. Larger number of samples leads to a better trace estimation. The computational const linearly increases with number of samples. |
| [in] | error_atol | Absolute tolerance criterion for early termination during the computation of trace samples. If the tolerance is not met, then all iterations (total of max_num_samples) proceed till end. |
| [in] | error_rtol | Relative tolerance criterion for early termination during the computation of trace samples. If the tolerance is not met, then all iterations (total of max_num_samples) proceed till end. |
| [in] | confidence_level | The confidence level of the error, which is a number between 0 and 1. This affects the scale of error. |
| [in] | outlier_significance_level | One minus the confidence level of the uncertainty band of the outlier. This is a number between 0 and 1. Confidence level of outleir and significance level of outlier are complement of each other. |
| [in] | num_threads | Number of OpenMP parallel processes. The parallelization is implemented over the Monte-Carlo iterations. |
| [in] | num_gpu_devices | Number of GPU devices to use. This is the number of CPU threads to be created to handle each GPU device in parallel for each CPU thread. |
| [out] | trace | The output trace of size num_inquiries. These values are the average of the rows of samples array. |
| [out] | error | The error of estimation of trace, which is the standard deviation of the rows of samples array. The size of this array is num_inquiries. |
| [out] | samples | 2D array of all estimated trace samples. The shape of this array is trace array. |
| [out] | processed_samples_indices | A 1D array indicating the processing order of rows of the samples. In parallel processing, this order of processing the rows of samples is not necessarly sequential. |
| [out] | num_samples_used | 1D array of the size of the number of columns of samples. Each element indicates how many iterations were used till convergence is reached for each column of the samples. The number of iterations should be a number between min_num_samples and max_num_samples. |
| [out] | num_outliers | 1D array with the size of number of columns of samples. Each element indicates how many rows of the samples array were outliers and were removed during averaging rows of samples. |
| [out] | converged | 1D array of the size of the number of columns of samples. Each element indicates which column of samples has converged to the tolerance criteria. Normally, if the num_samples used is less than max_num_samples, it indicates that the convergence has reached. |
| [out] | alg_wall_time | The elapsed time that takes for the SLQ algorithm. This does not include array allocation/deallocation. |
1 indicates successful convergence within the given tolerances was met. Convergence is achieved when all elements of convergence array are below convergence_atol or convergence_rtol times trace.0 indicates the convergence criterion was not met for at least one of the trace inquiries. Definition at line 205 of file cu_trace_estimator.cu.
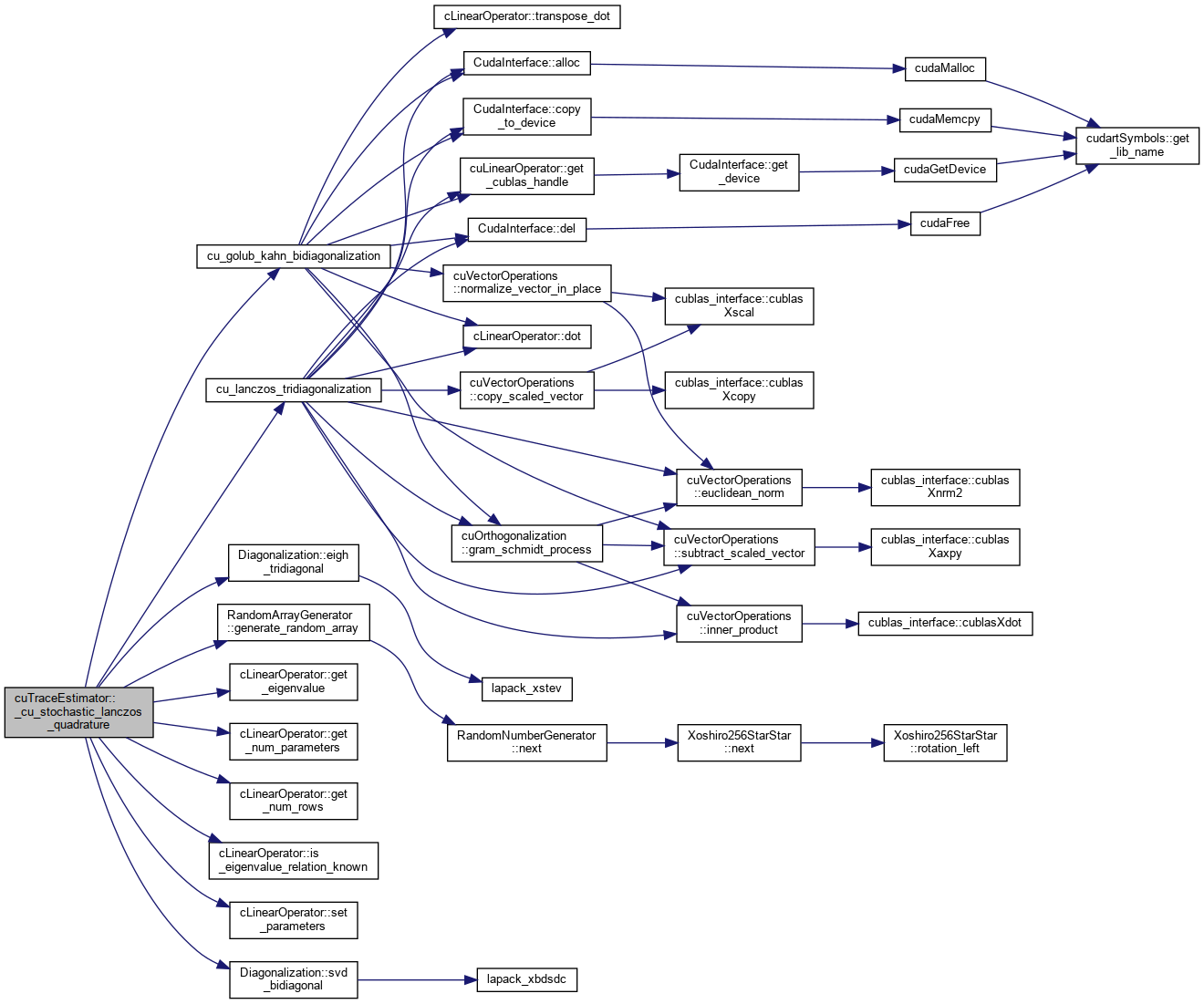
References cuTraceEstimator< DataType >::_cu_stochastic_lanczos_quadrature(), ConvergenceTools< DataType >::average_estimates(), ConvergenceTools< DataType >::check_convergence(), CudaTimer::elapsed(), cLinearOperatorBase::get_num_rows(), omp_get_thread_num(), omp_set_num_threads(), CudaAPI< ArrayType >::set_device(), CudaTimer::start(), and CudaTimer::stop().